Configurer votre profil au premier lancement
Au premier démarrage d'Apollia (ou après une réinitialisation), un parcours de configuration s'ouvre automatiquement. Il vous fait passer en quatre étapes — accueil, choix du profil, configuration de l'IA, calibrage conversationnel — pour qu'Apollia soit prêt à l'emploi. Durée totale : 3 à 8 minutes selon le téléchargement des modèles.
Cette page couvre le parcours initial uniquement. Pour éditer votre profil au quotidien depuis l'application installée, voir Mon profil.
Prérequis
- Apollia est installé et lancé pour la première fois (ou votre profil a été réinitialisé).
- Connexion internet active pendant l'étape Modèles si vous téléchargez un modèle local ou utilisez un fournisseur cloud.
Vue d'ensemble du parcours
Le parcours est rythmé par un rail de progression visible en haut de la fenêtre : Accueil · Profil · Modèles · Calibrage. Vous pouvez revenir en arrière à toute étape, et Configurer plus tard est disponible en bas pour ajourner l'ensemble.
| Étape | Ce qui s'y passe |
|---|---|
| Accueil | Présentation d'Apollia et lancement du parcours. |
| Profil | Choix entre Opérateur (interface simplifiée, validation explicite) et Builder (observabilité complète, SDK Python). |
| Modèles | Configuration du LLM (local GGUF avec téléchargement embarqué, ou fournisseur cloud) et, en option, du modèle de dictée vocale Whisper. |
| Calibrage | Conversation avec un agent qui collecte 4 informations rapides (nom, rôle, niveau de supervision, souveraineté des données) et propose des règles de permissions adaptées. |
Étapes détaillées
Étape 1 — Accueil
Au lancement, Apollia détecte qu'aucun profil n'existe et ouvre la fenêtre de configuration centrée sur l'écran.
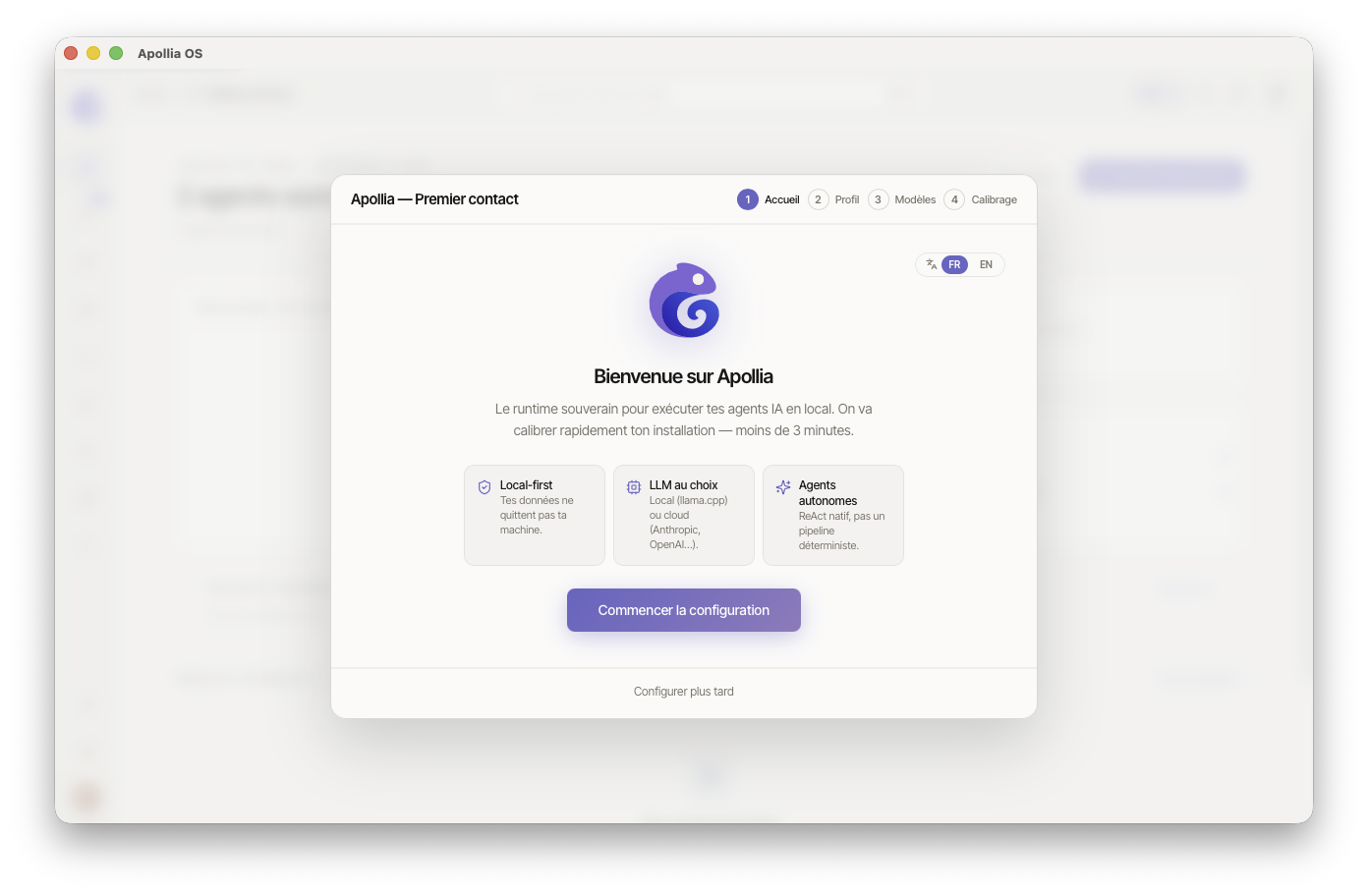
Lisez le bandeau de bienvenue, puis cliquez sur Commencer la configuration.
Étape 2 — Choisir votre profil
Deux cartes vous sont proposées côte à côte. Cliquez sur celle qui correspond le mieux à votre usage — vous pourrez le changer plus tard depuis Paramètres → Profil.
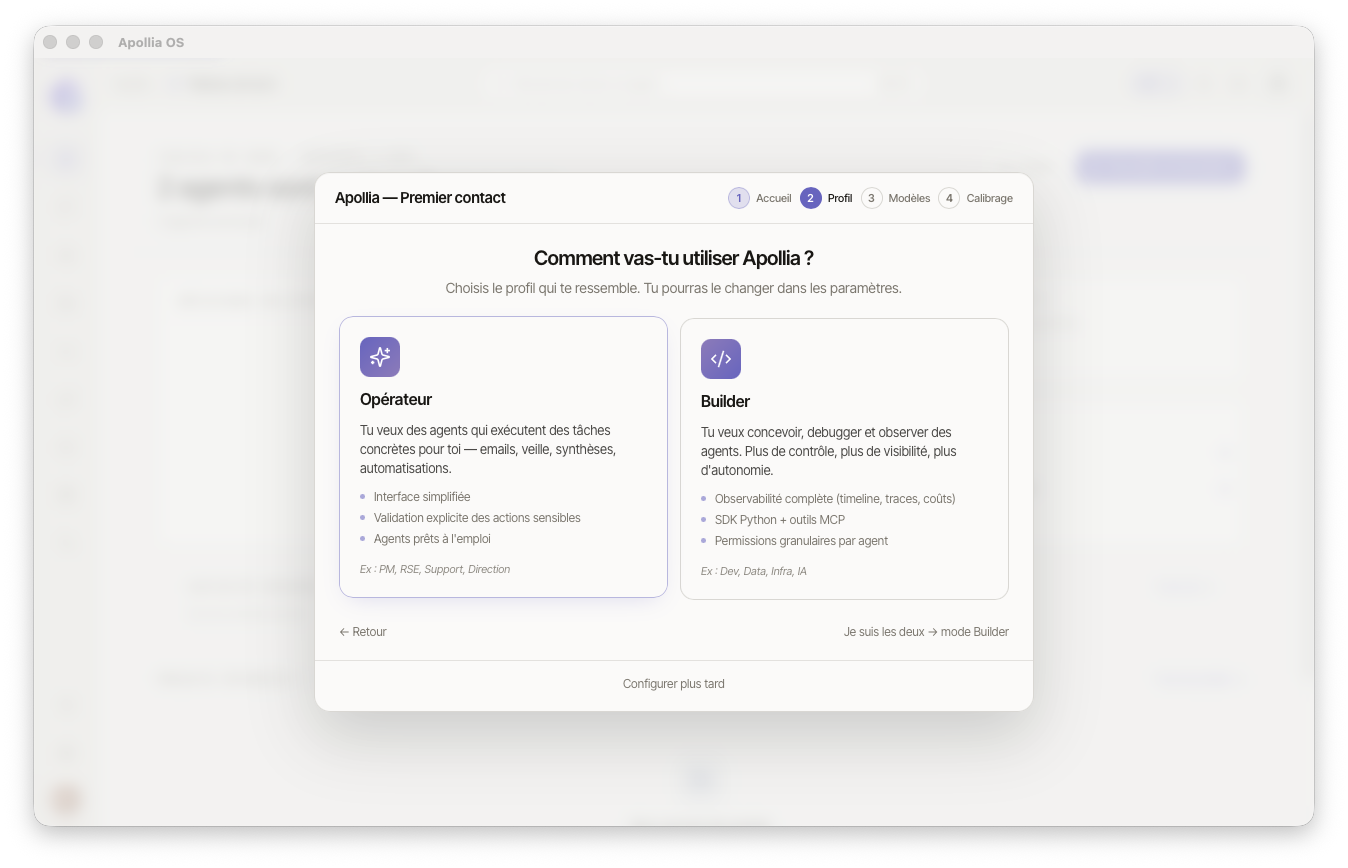
- Opérateur : pour qui veut des agents qui exécutent des tâches concrètes (emails, veille, synthèses) sans toucher à du code. Validation explicite des actions sensibles, agents prêts à l'emploi.
- Builder : pour qui veut concevoir, debugger et observer ses agents. Observabilité complète (timeline, traces, coûts), SDK Python, permissions granulaires.
Un lien discret en bas — Je suis les deux → mode Builder — permet de basculer en mode Builder si vous hésitez (le mode Builder expose toutes les fonctionnalités d'Opérateur en plus).
Étape 3 — Configurer le moteur d'IA
Cette étape calibre Apollia à votre matériel et à vos préférences de souveraineté. Un bandeau d'informations système (RAM, OS, GPU) apparaît en haut pour vous aider à choisir.
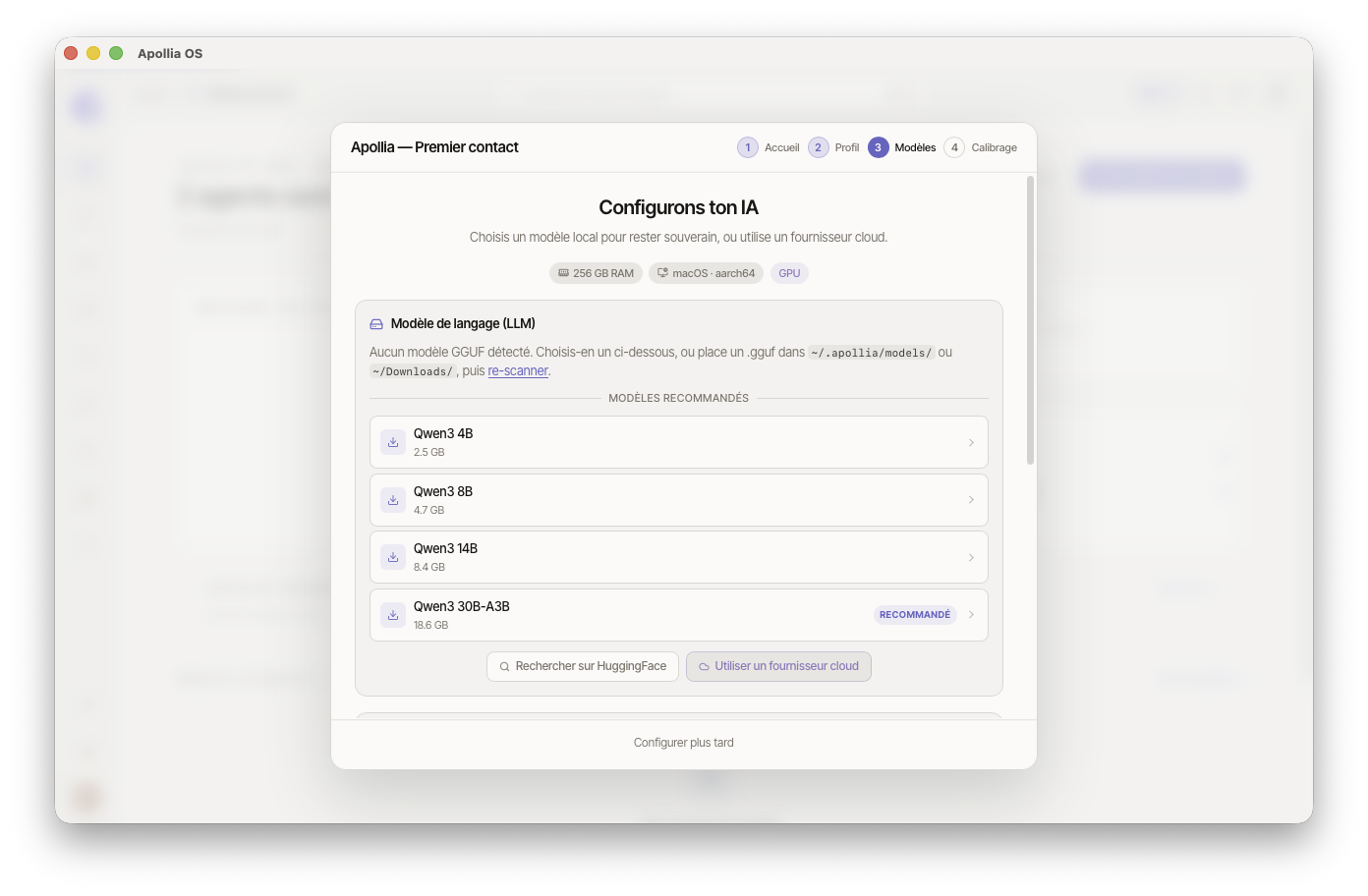
Section LLM (obligatoire)
Trois chemins possibles, selon votre situation :
- Modèles déjà présents sur la machine. Si vous avez déjà placé un fichier
.ggufdans~/.apollia/models/ou~/Downloads/, Apollia le détecte automatiquement. Cliquez sur la ligne correspondante pour le configurer en un clic. - Modèles recommandés à télécharger. Si aucun GGUF n'est trouvé, Apollia affiche une liste curée de modèles Qwen3 (4B, 8B, 14B, 30B-A3B) filtrée selon votre RAM, avec un badge Recommandé sur le plus pertinent. Cliquez sur la ligne pour lancer le téléchargement — une barre de progression avec débit en MB/s s'affiche, vous pouvez l'annuler à tout moment.
- Recherche HuggingFace. Le bouton Rechercher sur HuggingFace ouvre un mini-navigateur intégré : tapez le nom d'un modèle, dépliez les fichiers GGUF disponibles, et cliquez pour télécharger celui qui correspond à votre RAM (les fichiers sont étiquetés fits / might fit / too large).
- Fournisseur cloud. Le bouton Utiliser un fournisseur cloud ferme la fenêtre et vous emmène vers la page Backends LLM des paramètres pour brancher Anthropic, OpenAI ou Ollama. Une fois un backend ajouté, le parcours d'onboarding se rouvre automatiquement à cette même étape.
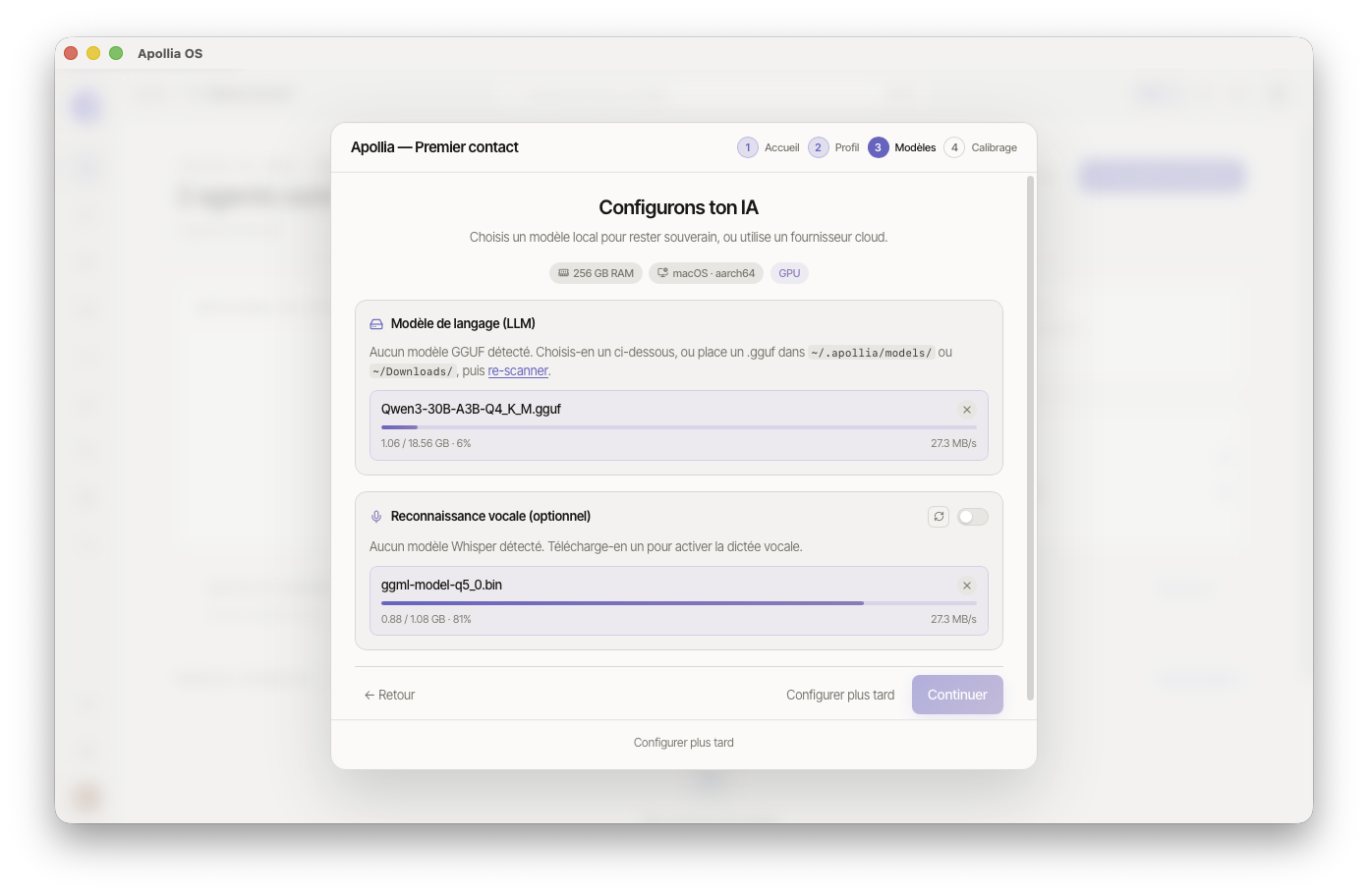
Une fois la configuration LLM réussie (badge vert Configuré ou liste de backends détectée), le bouton Continuer en bas devient actif.
Section Reconnaissance vocale (optionnel)
L'interrupteur Reconnaissance vocale active la dictée. Si aucun modèle Whisper n'est présent, vous pouvez en télécharger un depuis la liste curée :
| Modèle | Taille | Idéal pour |
|---|---|---|
| Whisper Tiny | 75 MB | Tests rapides, machines limitées |
| Whisper Base | 142 MB | Usage courant équilibré |
| Whisper Large-v3 Turbo Q5 | 547 MB | Recommandé — haute qualité, 6× plus rapide que Large-v3 |
| Whisper Large-v3 Q5 | 1.1 GB | Précision maximale, multi-langues |
| Whisper Large-v3 French | 1.1 GB | Fine-tuné spécifiquement pour le français |
Vous pouvez sauter cette section et l'activer plus tard depuis Paramètres → Reconnaissance vocale.
Boutons disponibles en pied de page
- ← Retour — revient à l'étape Profil.
- Configurer plus tard — saute directement au calibrage conversationnel (uniquement si un LLM est déjà disponible).
- Continuer — désactivé tant qu'aucun LLM n'est utilisable, devient actif dès qu'un backend cloud ou local est configuré.
Étape 4 — Calibrage conversationnel
L'agent d'onboarding s'ouvre dans la fenêtre. Il vous pose jusqu'à 4 questions, progressivement.
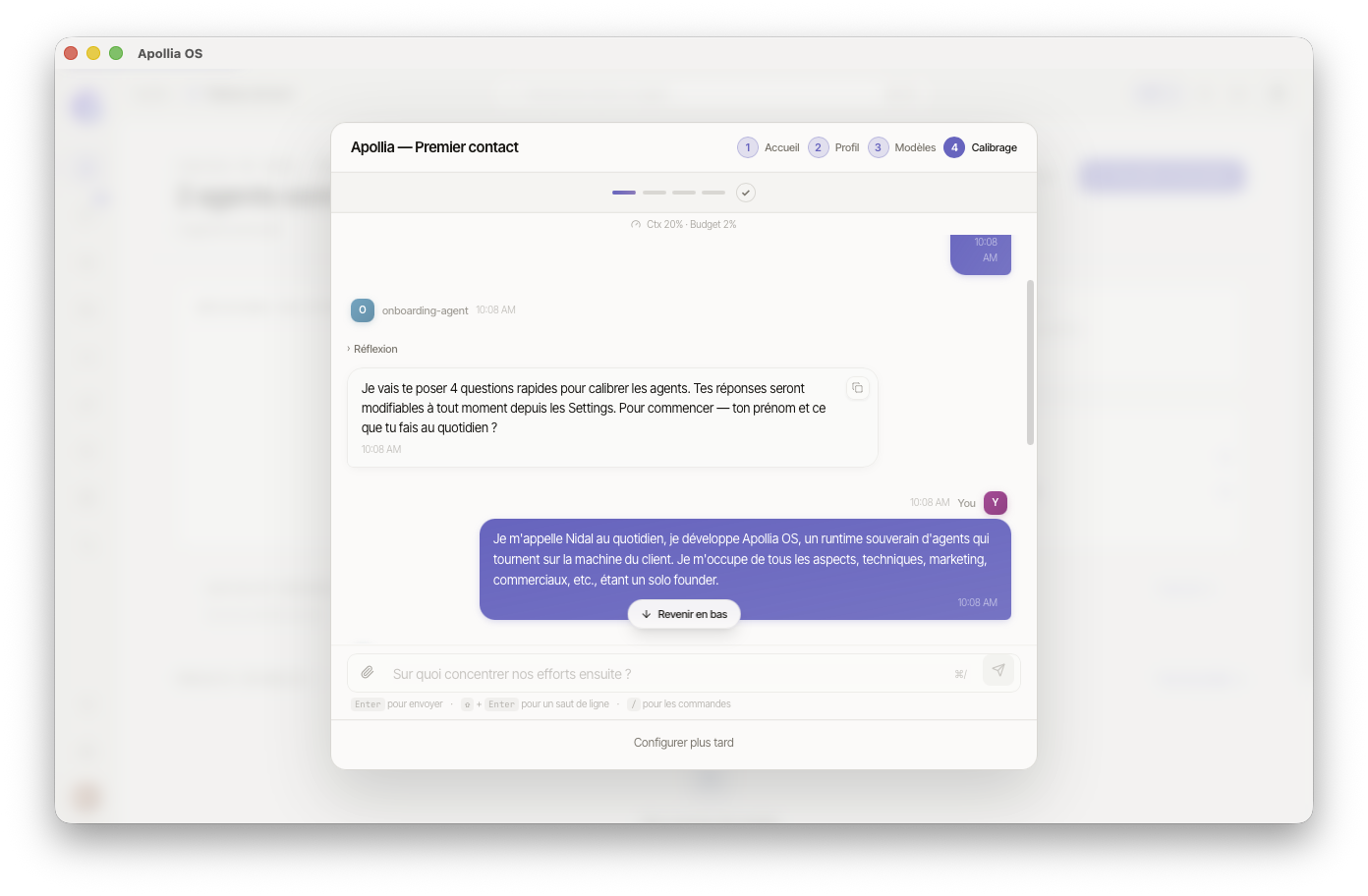
Les questions couvrent :
| Information collectée | Pourquoi |
|---|---|
| Votre nom ou alias | Les agents vous appellent par votre nom |
| Votre rôle | Les réponses et suggestions restent dans votre domaine |
| Niveau de supervision souhaité | Fréquence à laquelle les agents vous demandent une validation |
| Préférence de souveraineté des données | Avec ou sans services cloud tiers |
Répondez naturellement, sans formulation précise. Après la dernière question, l'agent dérive un jeu de règles de permissions à partir de vos réponses et les propose inline dans la fenêtre d'onboarding, juste avant le bouton « Terminer ». Chaque proposition est une mini-carte avec deux boutons :
- Approuver — la règle est enregistrée immédiatement dans la base
governance.dbavec l'auteuronboarding-agent. - Refuser — la règle est ignorée, aucune permission n'est créée. Vous pourrez toujours l'ajouter plus tard depuis Paramètres → Permissions.
Le bouton Terminer ne s'active que lorsque toutes les cartes ont été approuvées ou refusées — Apollia s'assure ainsi que vous avez vu chaque proposition.
Le nombre et la nature des cartes proposées dépendent de vos choix précédents :
| Vos choix | Règles proposées |
|---|---|
Souveraineté Local strict | deny http_fetch https:// et http:// (global) — bloque toute sortie réseau |
Souveraineté Local préféré | deny http_fetch sur api.openai.com et api.anthropic.com (global) — bloque les LLM cloud par défaut |
Souveraineté Cloud autorisé | aucune règle réseau |
Supervision Critique seulement ou Jamais | allow file_read (global) + allow shell_exec sur ls/cat/grep/pwd/head/tail — réduit la friction sur les actions en lecture |
Supervision Toujours valider | aucune règle d'allow — chaque action sensible déclenchera une carte d'approbation |
| Intégrations cochées (GitHub, Slack, Notion, Gmail) | allow http_fetch sur l'API correspondante (global) |
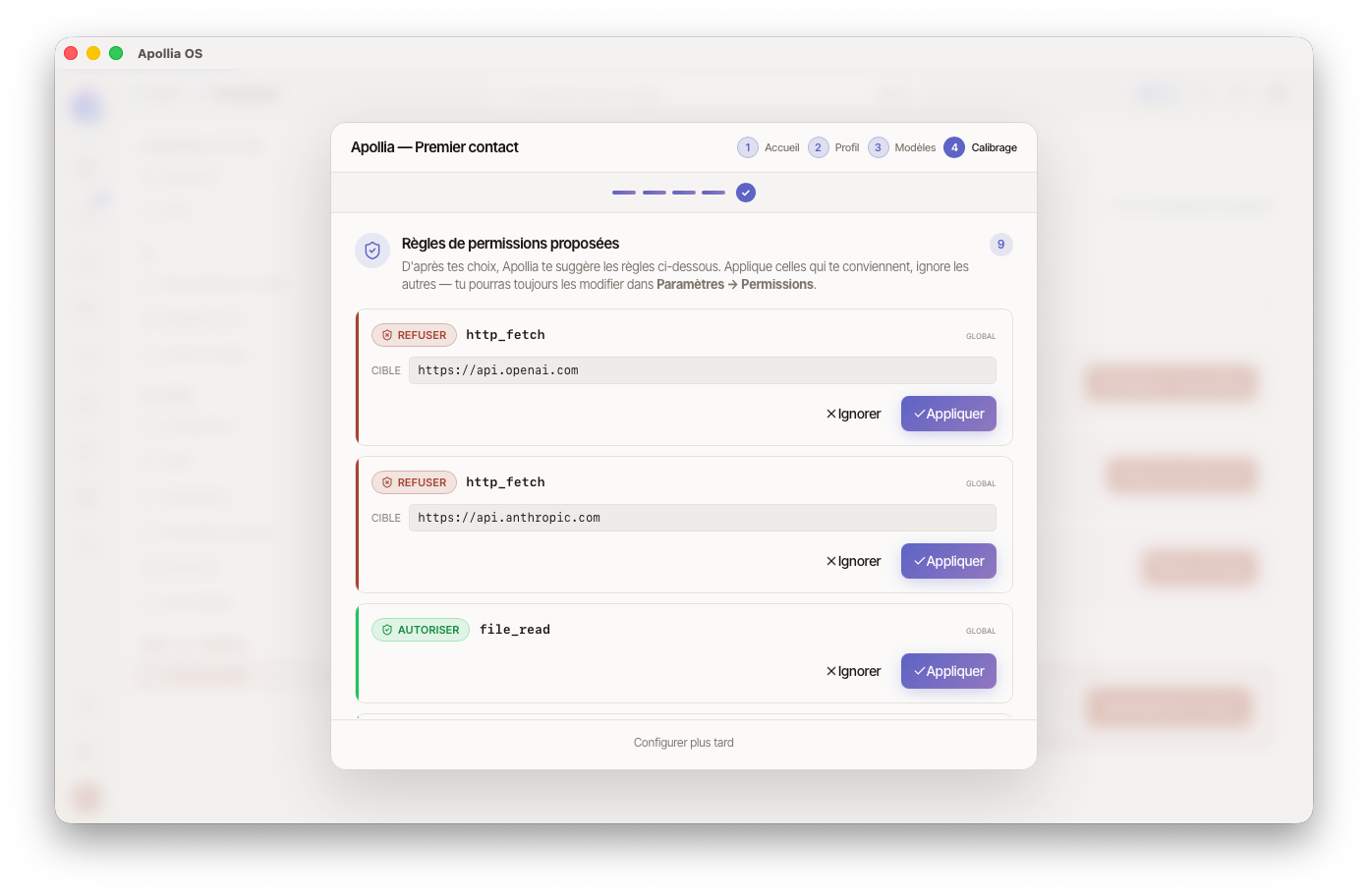
Une fois toutes les cartes traitées, la fenêtre se ferme automatiquement. Apollia est prêt.
Sauter le parcours
Si vous préférez configurer Apollia plus tard, cliquez sur Configurer plus tard (en bas de la fenêtre, disponible à toutes les étapes). Apollia s'ouvre normalement, mais sans LLM configuré le chat ne pourra pas répondre — vous devrez brancher un fournisseur depuis Paramètres → Backends LLM avant la première conversation.
Pour rouvrir le parcours après coup, voir la section Relancer le parcours ci-dessous.
Reprendre après une interruption
Le parcours est résumable : si vous quittez la fenêtre en cours de route (par exemple en cliquant sur Utiliser un fournisseur cloud pour ajouter un backend Anthropic), au retour Apollia reprend exactement à l'étape où vous étiez. La progression est persistée côté backend, pas en mémoire de session.
Relancer le parcours
Si vous avez significativement modifié votre profil (changement de rôle, de politique de souveraineté…) et souhaitez que vos règles de permissions soient recalibrées :
- Ouvrez Paramètres → Zone de danger.
- Cliquez sur Réinitialiser l'onboarding. Cette action efface uniquement les marqueurs de progression et de profil — vos backends LLM, modèles téléchargés et autres données restent intacts.
- Une fenêtre de confirmation demande de taper
RESET. Confirmez. - Le parcours en quatre étapes redémarre depuis l'Accueil.
Pour de petits ajustements (corriger votre nom, ajouter un outil quotidien, basculer une intégration) sans repasser le parcours, ouvrez directement Paramètres → Profil — voir Mon profil.
Réinitialiser entièrement Apollia
Le bouton Réinitialisation d'usine (zone danger, bas de page) supprime toutes vos données — agents, mémoire, modèles téléchargés, backends LLM, intégrations. Cette action ne peut pas être annulée. Voir Réinitialiser Apollia.
Vérification
Une fois le parcours terminé, ouvrez un chat et posez une question relative à votre domaine. L'agent vous appelle par votre nom et adapte sa réponse à votre contexte. Dans Paramètres → Permissions, les règles proposées lors du calibrage sont visibles, et dans Paramètres → Profil vous retrouvez l'ensemble des informations collectées, modifiables à tout moment.
Si ça ne marche pas
- La fenêtre ne s'ouvre pas au premier lancement : consultez les logs au démarrage. Si l'erreur évoque l'agent d'onboarding, redémarrez Apollia ; il est provisionné automatiquement à chaque lancement.
- Le bouton Continuer reste désactivé en étape Modèles : vérifiez qu'au moins un backend LLM est listé. Le téléchargement d'un GGUF doit être achevé (pastille verte Configuré), ou un backend cloud doit être ajouté via Utiliser un fournisseur cloud.
- Le téléchargement d'un modèle bloque à 0 % : vérifiez votre connexion internet, annulez avec le bouton X, puis relancez. Le débit attendu est de 5 à 50 MB/s selon votre lien.
- L'agent ne répond plus pendant le calibrage : fermez la fenêtre via Configurer plus tard et relancez depuis Paramètres → Zone de danger → Réinitialiser l'onboarding.
- Les règles de permissions ne s'appliquent pas : consultez Une action a été refusée.
Référence technique : Onboarding-System — spec complète des 4 étapes, persistence backend, commandes IPC, événements runtime.